Researchers at Qualcomm AI Research have unveiled “Spiffy,” a decoding technique that sharply cuts the inference time of diffusion-based large language models (dLLMs) without harming output quality. The team reports average acceleration of 2.8-3.1× on open-source models such as LLaDA-Base-8B, LLaDA-Instruct-8B, and LLaDA-1.5-8B. When combined with existing parallel-decoding tricks, Spiffy multiplies the gains to as high as 7.9×. Just as important, the method is lossless: formal proofs and empirical checks show it preserves the model’s output distribution. With near-negligible overhead and no need for a separate, lighter “draft” model, Spiffy aims to make dLLMs a faster—and more practical—alternative to autoregressive LLMs.
Why Diffusion LLMs Still Feel Slow
Most public large language models are autoregressive, predicting one token after another from left to right. Diffusion LLMs take a different approach. They start with a fully masked sequence and gradually “denoise” it, revealing tokens block by block. Because attention is bidirectional, dLLMs can, in principle, unmask many tokens in parallel. Commercial systems reportedly do so, generating thousands of tokens per second.
Yet open-source dLLMs, including the LLaDA family and Dream, usually unmask only one token per denoising step. This conservative setting maintains accuracy but demands a full forward pass for every token—a latency bottleneck that largely erases diffusion’s theoretical speed advantage.
Speculative decoding is a well-known fix for autoregressive models: a small “drafter” proposes several tokens, and the large “target” model verifies or rejects them in one batch. Porting that idea to dLLMs is not straightforward. Tokens influence each other in both directions, and verification must account for joint probabilities over entire blocks. Spiffy re-tools speculation to fit this new landscape.
How Spiffy works
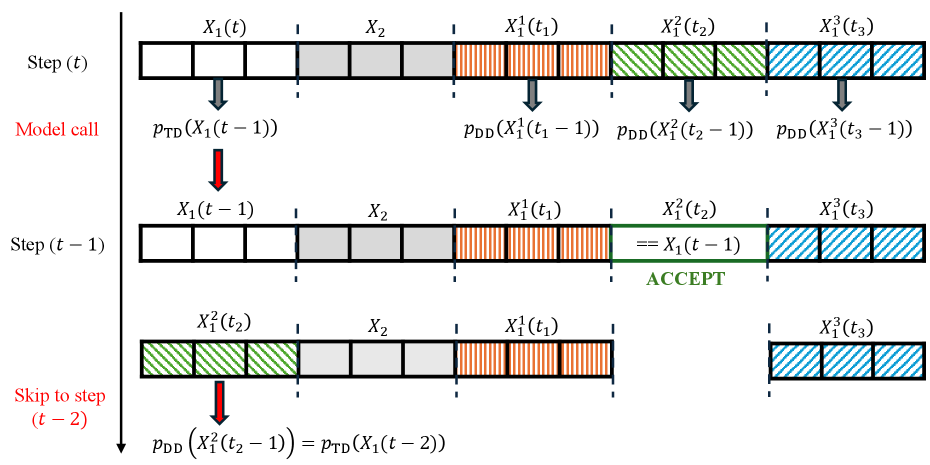
Spiffy’s lossless verification allows X1(t) to advance to state X1(t-2) with a single model inference. Draft blocks X11, X12, X13 are appended to the end of the sequence, and model inference is performed in parallel. Each draft is compared against X1(t-1) to check for acceptance. Since we have access to any accepted draft’s distribution at time t-2, we can skip ahead and directly predict X1(t-2). This process is then repeated with the remaining drafts for further acceleration.
At a high level, Spiffy follows a “draft-then-verify” loop over the denoising timeline. The novelty lies in three design choices that fit the diffusion setting:
- Auto-speculation. Instead of training a separate drafter, Spiffy samples its drafts directly from the current dLLM distribution. The target model therefore doubles as its own drafter, eliminating both training cost and runtime memory overhead.
- Draft blocks, not single tokens. Because diffusion models unmask several positions that all depend on each other, Spiffy drafts blocks. Each draft represents the entire block at a future timestep, preserving bidirectional dependencies during verification.
- Directed draft graphs. Spiffy arranges its drafts in a graph rather than a tree. A child node may have multiple parents—reflecting the fact that several earlier states can lead to the same future state. This structure raises the odds that at least one path will be accepted, allowing Spiffy to skip multiple timesteps per verification call.
The verification step is lossless. For each draft, Spiffy computes the exact conditional probability at its next timestep (all in one forward pass thanks to a custom attention mask). A simple rejection-sampling rule keeps or discards the draft so that the resulting sequence distribution matches vanilla decoding. Formal proofs and empirical tests on GSM8K, HumanEval, MATH, and MBPP found no measurable change in accuracy.
Calibrated Draft graphs
A key ingredient is choosing which draft blocks to include. The space is huge: for a block of length L there are L × V ways to unmask the next token position and value. Spiffy tackles that with an offline calibration routine:
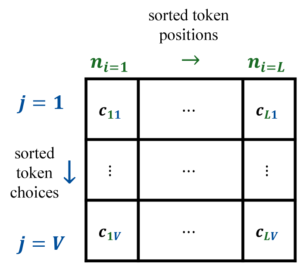
- The researchers run the dLLM in its regular, slow mode on a small calibration set (20–50 samples suffice).
- At every timestep, they log the ranking of token positions (i) and vocabulary choices (j) that the model actually unmasked.
- They aggregate the most frequent (i, j) pairs across a “look-ahead” horizon of ℒ timesteps and build a dense “all-possibilities” graph.
- From that graph they select an optimal subgraph of D nodes (draft formulas) that maximizes how often parent–child drafts co-occurred during calibration.
The result is a reusable directed graph that guides Spiffy throughout generation. Calibration takes under 30 minutes on a single GPU and never touches test data, preventing leakage. Figure 1 shows an example graph for HumanEval at D = 10; it starts with a single high-confidence token, then fans out into combinations that the model often picks next.
Experimental results
Spiffy was evaluated on three 8-billion-parameter dLLMs—LLaDA-Base-8B, LLaDA-Instruct-8B, and LLaDA-1.5-8B—using four common benchmarks. Each task generated up to 256 tokens with 32-token blocks. The table below summarizes results for the largest draft budget (D = 10); the paper gives similar trends for D = 3, 5, 8.
| Model + dataset |
Baseline speed |
Speed with Spiffy (D = 10) |
Main accuracy metric |
| LLaDA-Base-8B / HumanEval |
1.00 × |
3.07 × |
pass@1 unchanged at 0.45 ± 0.05 |
| LLaDA-Instruct-8B / GSM8K |
1.00 × |
3.04 × |
exact_match unchanged at 0.53 ± 0.03 |
| LLaDA-1.5-8B / MBPP |
1.00 × |
2.93 × |
pass@1 unchanged at 0.38 ± 0.03 |
Even with only three draft nodes (D = 3), speedups reached 2.24–2.40×, confirming that the calibrated graph is effective in a tight budget.
Multiplying other parallel-decoding tricks
Diffusion models can already speed up by unmasking more than one token at a time. The team showed that Spiffy multiplies those gains. For LLaDA-Instruct-8B on HumanEval:
| Base decoding scheme |
Scheme speedup |
Combined with Spiffy |
pass@1 |
| Hard-coded 2 tokens/step |
2.00 × |
3.74 × |
0.43 ± 0.05 |
| Hard-coded 4 tokens/step |
4.00 × |
5.28 × |
0.29 ± 0.05 |
| Threshold 0.7 (fast-dllm style) |
6.43 × |
7.88 × |
0.45 ± 0.05 |
The threshold-0.9 configuration paired with Spiffy delivered a 5.18× speedup—on par with always unmasking four tokens but at much higher accuracy (0.50 vs. 0.29). Because Spiffy is agnostic to the denoising schedule, the same calibration graph worked out of the box, suggesting further gains are possible by re-calibrating specifically for each schedule.
Overheads and practical considerations
- Runtime cost. Draft selection and verification add just 0.2 – 3.8 % to each forward pass—far smaller than the saved NFEs.
- Calibration data. Fewer than 50 samples are enough to stabilize the graph. Acceptance rates were consistent across all 32-token blocks, with later blocks even benefiting more as the model conditions on extra context.
- Losslessness. Small numerical differences (<10-5) in BF16 matrix muls caused rare token mismatches, but all downstream exact-match and pass@1 scores stayed within statistical noise.
What is Next?
The Qualcomm team positions Spiffy as a modular plug-in. Because it relies neither on extra parameters nor on architectural tweaks, it can coexist with future optimizations: key-value caching, smaller diffusion drafters, or even solvers that cut the number of diffusion steps. The authors note that speculative graphs calibrated on one dataset often transfer well to others, simplifying deployment.
Diffusion models promise parallel generation but have struggled to deliver open-source speed. By re-imagining speculative decoding for the bidirectional, block-wise world of dLLMs, Spiffy closes much of that gap—while keeping the mathematical guarantees that enterprise users demand.
