A research team led by Beijing University of Posts and Telecommunications, working with Nanyang Technological University and several national key laboratories, has introduced Tiny-R1V-3B, a 3-billion-parameter model that claims to bring large-model style multimodal reasoning to devices with far fewer resources. According to the team, Tiny-R1V matches or outperforms state-of-the-art open-source systems on ten popular benchmarks while generating answers with roughly half the tokens—and therefore less latency—than today’s reinforcement-learning models of comparable size.
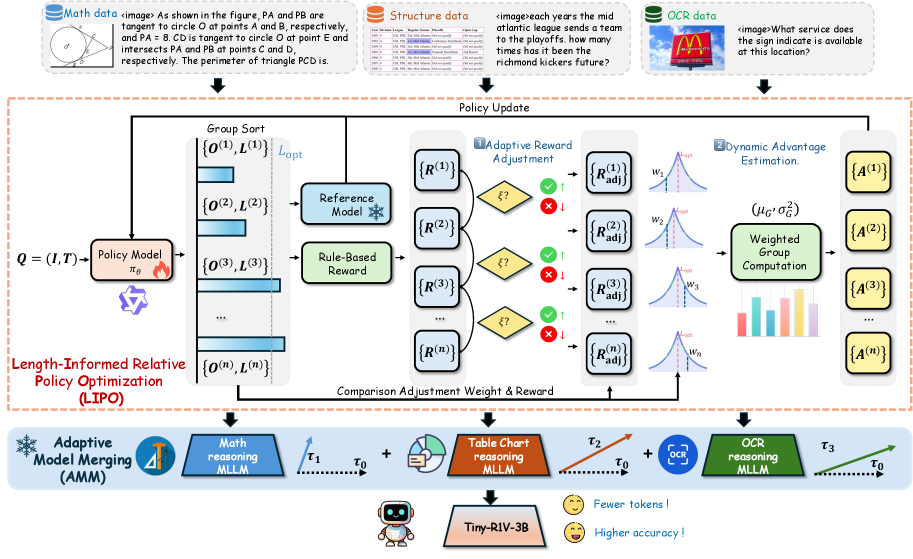
The work combines two ideas. First, a reinforcement-learning procedure called Length-Informed Relative Policy Optimisation (LIPO) rewards the model for being brief and correct, trimming the typical “chain-of-thought” scaffolding. Second, a training-free method dubbed Adaptive Model Merging (AMM) fuses separate specialist models—math, structured-data reasoning, and optical-character recognition—into a single network without extra data or compute. Together, the methods deliver a 0.8-point average gain over the best previous merging approach and a 4.9-point gain over classical task-arithmetic merging, all in a footprint suited to commodity GPUs or even high-end laptops.
Why lightweight models matter
Multimodal large language models (MLLMs) are quickly becoming the default interface for querying complex documents, diagrams and photographs. Yet the leading research systems—often 10 B parameters or more—run comfortably only on datacenter hardware. Smaller models exist, but they usually sacrifice reasoning depth or require long and costly thought chains, a phenomenon researchers sometimes call “over-thinking.” Tiny-R1V aims to break this trade-off, arguing that the right learning signals and architectural tweaks can unlock stronger logic without scaling up parameters.
Practically, a 3-billion-parameter network can execute on a single modern GPU or even in mixed-precision on some edge devices. For interactive use—reading a PDF table, checking a handwritten note, or explaining a chart in a slide deck—lower latency and lower memory translate into better user experience and wider deployment options.
A two-stage recipe: LIPO and AMM
Stage 1: making brevity pay with LIPO
Reinforcement learning from human or rule-based feedback has become a preferred fine-tuning tool for reasoning. Standard frameworks such as Group Relative Policy Optimisation (GRPO) reward correct answers but remain agnostic to how many tokens the model uses to arrive there. The researchers argue that this creates a perverse incentive: longer chain-of-thought outputs receive the same reward as concise ones, so the model drifts toward verbosity.
LIPO adds an explicit length signal to the reward. Within each group of candidate answers the method
- identifies pairs whose quality scores differ by less than a user-set threshold,
- boosts the reward of the shorter answer by a factor that decays smoothly as its length approaches an upper bound,
- computes a dynamic “advantage” that weights each answer by how close its length is to an automatically selected optimum for the group.
This subtle nudge proved to be enough to cut the average reasoning trace on the MathVista benchmark from 138 tokens (baseline GRPO) to 83 tokens, all while inching the accuracy up by 0.4 points. On MathVision, token count collapsed from roughly 440 to 115—less than one-third— with a 2.5-point accuracy bump.
Stage 2: fusing experts with AMM
Multimodal tasks are diverse: geometry questions differ markedly from OCR transcription. Finetuning a single network on all data sometimes leads to “catastrophic forgetting,” whereas keeping separate experts multiplies the memory burden. Model-merging techniques have therefore become popular because they re-combine the parameter deltas (task vectors) of each expert back into the base model weights.
AMM extends the recent WUDI-merging line in two ways:
- Dual weighting. Each task vector receives an inherent importance weight (derived from its parameter norm) and a compatibility weight that changes at every optimisation step to reflect how well that vector aligns with the current merged direction.
- Gradient-projection regularisation. During the layer-by-layer optimisation, AMM penalises gradient components that are orthogonal to any task vector, effectively steering the merge along directions already validated for individual tasks and reducing destructive interference.
The procedure is training-free in the sense that it does not revisit original logits or data—only the weight matrices—so it finishes in minutes on a workstation.
How Tiny-R1V performs against previous approaches
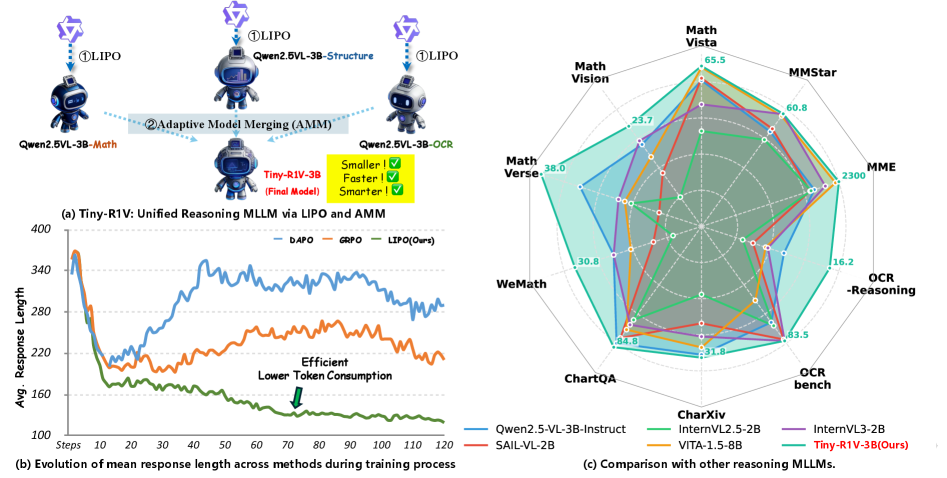
The team evaluated Tiny-R1V on ten public benchmarks spanning maths diagrams, tables, scientific charts, scanned documents and general visual question answering. A distilled comparison appears below.
| Model / Method |
Params (B) |
Avg. Score
(10 benchmarks) |
Avg. Tokens
(MathVista) |
| Qwen2.5-VL-3B-Instruct (baseline) |
3 |
47.8 |
87.5 |
| WUDI Merging on three experts |
3 |
50.8 |
— |
| Tiny-R1V-3B (LIPO + AMM) |
3 |
51.6 |
84.5 |
The gains are modest in absolute terms—0.8 points over the best earlier merge—but broad, appearing in eight of ten tasks. Importantly, they come with shorter outputs, which directly translate into reduced inference time. On the OCR-Reasoning set, Tiny-R1V lifted accuracy to 16.2% compared to 12.8% for a mixture-trained baseline and 12.0% for task arithmetic merging.
Even outside its specialist domains, the model held its own. On the general-ability MMStar benchmark it tied higher-capacity competitors like VITA-1.5-8B despite using less than half the parameters.
What it means for real-time multimodal applications
Developers are hungry for models that can handle screenshots, webpages and worksheets with minimal latency. By incentivising concise reasoning and offering a no-data merge path, Tiny-R1V suggests a practical recipe:
- start with a competent visual language base like Qwen2.5-VL-3B-Instruct,
- reinforce individual capabilities under LIPO to keep answers punchy,
- merge them via AMM to ship a single checkpoint.
Edge devices stand to benefit the most. A 3-B model can already fit into the memory budget of high-end smartphones when quantised, and the reduced token count further lowers compute per query. For cloud providers, faster responses mean higher throughput and lower cost per interaction.
Looking ahead
Tiny-R1V shows that thoughtful reward engineering and weight-space geometry can stretch the limits of small multimodal models. The authors note a few open issues: performance on free-form OCR still lags behind larger models, and the merge procedure currently assumes all experts share the same base initialisation. Future work may explore dynamically routing inputs to partial experts instead of fully merging weights, or applying the same framework to audio-text tasks.
Still, by reducing token overhead by up to two-thirds in some settings and avoiding extra data cycles, the approach offers an attractive middle ground between heavyweight proprietary MLLMs and bare-bones small models.
You can read the full paper on arxiv.org
