A research team drawn from NVIDIA has released “LongLive,” a 1.3-billion-parameter, frame-level autoregressive (AR) model that claims real-time generation of videos up to four minutes long while letting users update the prompt mid-stream. Running on a single NVIDIA H100 GPU, LongLive delivers 20.7 frames per second and, according to the authors, outperforms state-of-the-art diffusion and autoregressive baselines on VBench and VBench-Long quality metrics, all with a smaller memory footprint enabled by INT8 quantization. The work, published this week on GitHub, positions causal AR modeling as a practical alternative to diffusion systems for long-form, interactive video synthesis.
Why Long Video Generation is Hard?
Most high-fidelity text-to-video (T2V) models rely on diffusion networks that calculate bidirectional attention across every frame. Quality is strong, but the cost scales quadratically: a single 60-second clip can take tens of minutes on a top-tier GPU. Causal AR models, in contrast, build a video frame by frame and can reuse key–value (KV) attention caches, cutting compute substantially. Yet existing AR models typically train on five-second snippets, so quality degrades once inference stretches past a few clips. Worse, if a user tries to change the prompt mid-generation—“the dog turns into a robot” after 10 seconds—the cached context often locks the model into the old concept or produces a jarring transition.
LongLive tackles both the efficiency and the interaction gaps with three core ideas: KV re-caching, streaming long tuning, and an attention design that pairs short windows with a “frame sink.” Together, these ingredients let the researchers fine-tune the open-source Wan2.1-T2V-1.3B short-clip model into LongLive in roughly 32 GPU-days, then stream out 240-second videos without visible drift.
Inside LongLive’s toolkit
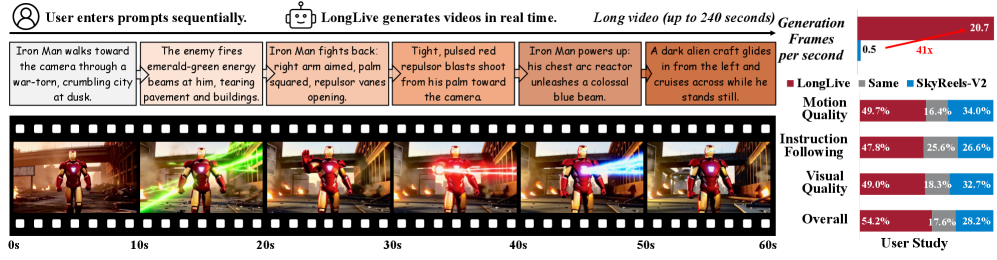
LongLive accepts sequential user prompts and generates corresponding videos in real time, enabling user-guided long video generation. The 60-second sequence shown is an example, LongLive supports up to 240-second videos in a single H100 GPU.
1. KV Recache for clean prompt switches
In a causal transformer, each frame’s representation is stored as keys and values that the model attends to at subsequent steps. Simply wiping the cache forces the model to honor a new prompt but breaks temporal continuity; keeping it intact preserves motion but dilutes the new prompt. KV Recache takes a middle path: when the prompt changes, the engine reruns the already-generated frames through its cross-attention layers, this time conditioned on the new text embedding. The refreshed cache carries over the immediate visual state—positions, lighting, motion trajectories—while flushing residual semantics tied to the old prompt. The recache cost is paid only once per switch and adds about 6 % to run-time during training.
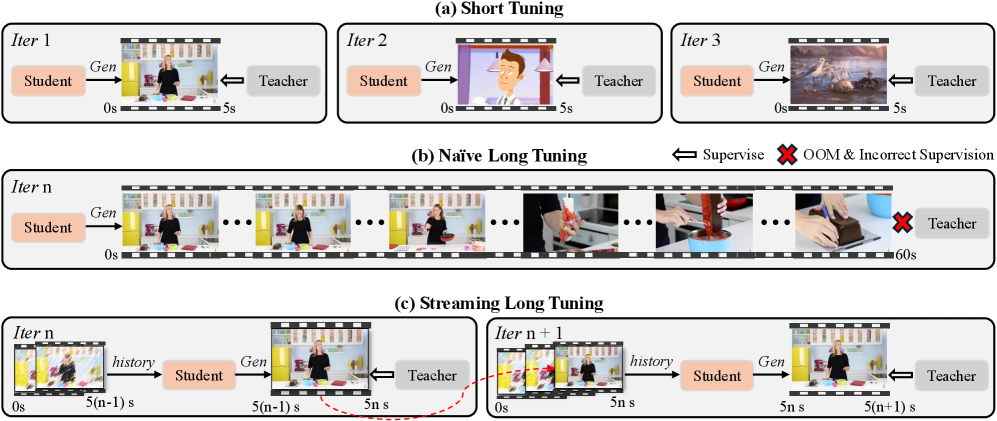
2. Streaming long tuning to close the train–test gap
Training directly on full-length videos would overwhelm GPU memory and yield noisy teacher supervision. Instead, the researchers extend the “self-forcing” distillation pipeline: the student model generates a five-second clip, the teacher (the original Wan2.1 network) provides per-step guidance, and gradients flow only through that clip. The newly created frames are then detached and fed back as fixed context for the next five-second segment, continuing until the sequence hits 60 seconds. Because the student repeatedly conditions on its own imperfect history—just like at inference—error accumulation is learned away during training.
3. Short-window attention with a frame sink
Restricting attention to the most recent W latent frames slashes complexity from quadratic in sequence length to O(W), but breaks long-range coherence if W is too small. LongLive sets W = 9 frames (roughly half a second) and permanently appends the first three frames as global “sink” tokens in every self-attention layer. These sinks anchor the scene’s identity and background, so the model can focus most computation on local motion without losing high-level consistency. In ablation, a 9-frame window plus a 3-frame sink matched the quality of a 21-frame full window while cutting compute by 28 % and peak memory by 17 %.
How the Numbers Stack Up
The team benchmarked LongLive against representative diffusion and AR systems, all open-sourced and running at similar 832 × 480 or higher resolutions. Metrics come from VBench for five-second clips and VBench-Long for thirty-second clips. Throughput was measured on one H100 GPU.
| Model (resolution) |
Params |
Frames / s |
VBench total |
VBench-Long total |
| LTX-Video 768×512 (diffusion) |
1.9 B |
9.0 |
80.0 |
— |
| Wan2.1 832×480 (diffusion) |
1.3 B |
0.8 |
84.3 |
— |
| SkyReels-V2 960×540 (AR-diffusion) |
1.3 B |
0.5 |
82.7 |
75.3 |
| Self-Forcing 832×480 (AR) |
1.3 B |
17.0 |
84.3 |
81.6 |
| LongLive 832×480 (AR) |
1.3 B |
20.7 |
84.9 |
83.5 |
On interactive 60-second evaluations with a prompt switch every 10 seconds, LongLive’s overall quality score reached 84.4, beating Self-Forcing by 1.9 points and SkyReels-V2 by 3.9. Meanwhile, CLIP semantic similarity stayed above 24.2 across all six segments, signaling faithful prompt adherence throughout the transitions. Qualitative samples published by the team show smooth cross-fades—an astronaut seamlessly morphs into a medieval knight, or a day-time cityscape turns to neon-lit cyberpunk—without the “ghost frames” or identity drift often seen in earlier AR runs.
What the Results Mean for Builders
The headline is speed: 20.7 FPS for 832 × 480 output lets LongLive v1.3B feed a consumer livestream or an interactive creative tool in real time on a single H100. The researchers also demonstrate INT8 post-training quantization, trimming model weight size from 2.7 GB to 1.4 GB with negligible loss—an important win for cloud cost or edge deployment. Because the architecture remains transformer-based, it can inherit future advances in tokenizer design, motion-aware LoRA adapters, or multi-modal conditioning signals (e.g., sketches, audio cues).
Equally notable is the training recipe: streaming long tuning required only 12 hours on 64 × H100 GPUs to push the base short-clip model to minute-long competence. That is well inside the budget of many applied-research labs and signals that large-scale, long-form T2V might follow the same democratization curve we have seen with language models: start from an open checkpoint, graft a smart curriculum and memory strategy, and reach respectable performance without reseeding from scratch.
Limitations and Next Steps
The authors acknowledge several open issues. First, LongLive still caps out at 240 seconds on a single GPU; extending further would either require memory partitioning across devices or new compression tricks. Second, the model’s resolution remains 832 × 480. Scaling to 1080p and beyond may stress the current short-window budget unless window size or token-per-pixel ratio is revisited. Third, while KV Recache works for hard prompt boundaries, more nuanced transitions—gradual stylistic shifts or multi-speaker narratives—might benefit from softer attention-mask schedules rather than an immediate cache rebuild.
Future work hinted by the team includes bringing audio into the loop, leveraging NVIDIA’s Riva speech stack to synchronize lip motion, and experimenting with personalized LoRA layers so that users can drop in custom characters without retraining the full network. Because the code and weights are Apache 2.0 on GitHub, outside groups can test those directions quickly.
Source: “LongLive: Real-Time Interactive Long Video Generation,” NVIDIA, MIT, HKUST (GZ), HKU, Tsinghua University, 2024. Repository and demo videos: https://github.com/NVlabs/LongLive.
