A research team inside Alibaba Group’s Institute for Intelligent Computing has released “Qwen-Image,” an image-generation model that focuses on something text-to-image systems still struggle with: placing long, legible passages of text inside the pictures they create.
According to the team’s technical report, the new model renders multi-line English, Chinese and mixed-language copy with markedly higher accuracy than leading commercial services while also offering state-of-the-art performance on standard image-editing tasks. The researchers have open-sourced Qwen-Image on Hugging Face and ModelScope, positioning it as a community alternative to proprietary APIs such as OpenAI’s DALL·E 3 or Google’s Imagen 4.
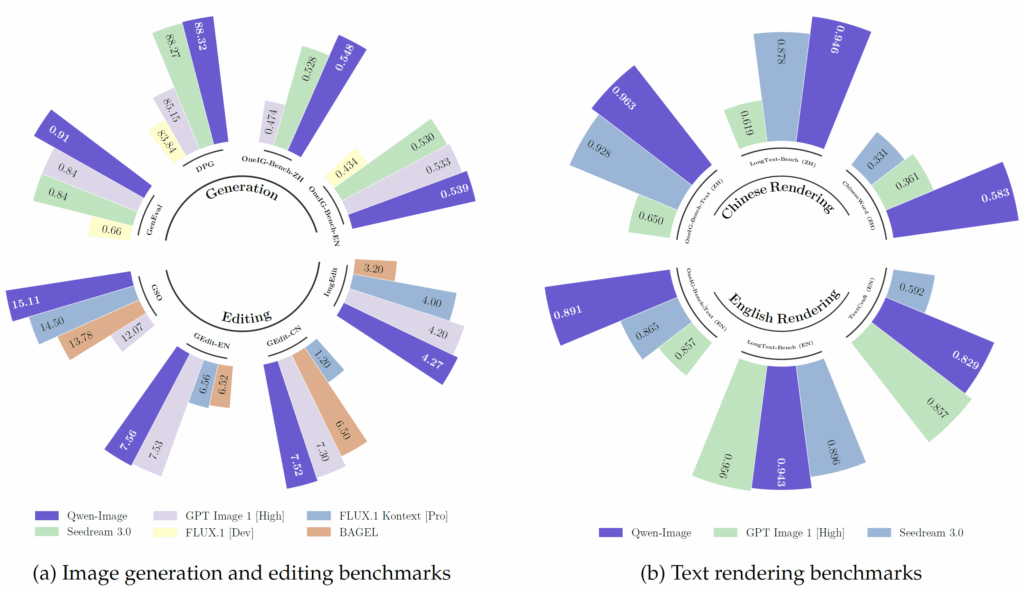
Current benchmark against-(1)Seedream3.0,(2) GPT Image 1, (3) Flux.1 Kontext, (4) Bagel and (5) Flux.1 [dev] – Shows Qwen-Image outperforming all of these models is every way. This can also be seen in the text rendering benchmark.
Why text inside images is a hard problem

Modern diffusion models excel at photorealistic textures and artistic styles, yet they routinely misspell shop signs, book covers or presentation slides. The reason is simple: most public datasets supply captions that describe a scene, not the exact glyphs that appear within it. Without explicit character-level supervision, even large models “learn” text primarily as abstract shapes rather than discrete symbols. That gap becomes more obvious in logographic languages such as Chinese, where thousands of low-frequency characters rarely show up in training data.
Qwen-Image targets the issue head-on. The Alibaba group built a dedicated pipeline that gathers natural images, designs synthetic layouts and balances rarely seen characters so the model sees them often during training. It then schedules the learning process from “easy” primitives (simple shapes, no text) to “hard” ones (paragraph-length, multi-font layouts) in what the authors describe as a curriculum strategy. The end result, they claim, is native text rendering comparable to human typesetting in both alphabetic and logographic scripts.
What Qwen-Image Brings to the Table?
1. A VAE that keeps the small print sharp
Qwen-Image relies on a variational auto-encoder (VAE) that compresses a 1,328-pixel image down to 16 latent channels on an 8×8 grid. The team fine-tuned only the decoder on a private corpus of documents, posters and synthetic paragraphs, then balanced pixel-wise reconstruction loss with a “perceptual” loss so that the grid artifacts common in VAEs all but disappear. In their evaluation, the VAE reaches 33.4 dB PSNR on ImageNet and 36.6 dB on a text-heavy set, outperforming larger encoders from Hunyuan or Stable Diffusion 3.5.
2. Dual encoders for semantics and pixels
During editing, the system feeds the original image into two distinct encoders. Alibaba’s Qwen 2.5-VL — a vision-language large model — extracts high-level semantics (“this is a street sign that should read ‘Café’”). Simultaneously, the frozen VAE captures low-level color and structure. Both streams condition a Multimodal Diffusion Transformer (MMDiT) backbone. The design lets the model modify only what the user asks for while leaving the rest of the picture untouched.
3. Multimodal positional encoding
To help the transformer differentiate between thousands of visual patches and dozens of text tokens, the researchers propose Multimodal Scalable RoPE. Here, text tokens are mapped diagonally across the image grid so their position never overlaps with any specific row or column of pixels. The method keeps training stable at multiple resolutions without choosing a “magic row” where text begins.
4. Producer–consumer training at scale
Running a 20-billion-parameter backbone required streaming terabytes of filtered data without stalling GPUs. The group split the workload into Ray-like producers (which clean, encode and store samples) and consumers (which only train). A custom HTTP layer passes batches in zero-copy mode while Megatron-LM handles 4-way tensor parallelism on the consumer side.
How well does it work?
Across public evaluations, Qwen-Image usually matches or beats proprietary APIs. Below is a snapshot of the numbers quoted in the research.
| Benchmark |
What it measures |
Best closed model cited |
Qwen-Image |
| DPG overall score |
Prompt adherence (1,000 dense prompts) |
Seedream 3.0 – 89.84 |
92.78 |
| GenEval object-attribute score |
Compositional accuracy |
Seedream 3.0 – 0.84 |
0.91 |
| OneIG-Bench (English) overall |
Alignment, reasoning, style, diversity |
GPT Image 1 – 0.539 |
0.650 |
| ChineseWord accuracy |
Single-character Chinese rendering |
Seedream 3.0 – 33 % |
58 % |
| AI Arena Elo rating* |
Human pairwise votes, 5 k prompts |
Imagen 4 Ultra Preview 0606 – top |
3rd place, ~30 Elo above GPT Image 1 |
*AI Arena is an open leaderboard operated by Alibaba; the team reports every model has >10,000 comparisons.
On image editing, the model reaches the highest overall score on GEdit (7.56 out of 10) in both English and Chinese tasks and leads the nine-task ImgEdit benchmark with an average 4.27 out of 5. Even on novel-view synthesis — a typical 3-D problem — Qwen-Image posts 15.11 PSNR, surpassing specialized tools such as Zero-123 and ImageDream.
How to Install
The first step would involve installing the latest version of diffusers –
pip install git+https://github.com/huggingface/diffusers
The below code shows how you can use Qwen-Image-Edit-2509
import os
import torch
from PIL import Image
from diffusers import QwenImageEditPlusPipeline
pipeline = QwenImageEditPlusPipeline.from_pretrained(“Qwen/Qwen-Image-Edit-2509”, torch_dtype=torch.bfloat16)
print(“pipeline loaded”)
pipeline.to(‘cuda’)
pipeline.set_progress_bar_config(disable=None)
image1 = Image.open(“input1.png”)
image2 = Image.open(“input2.png”)
prompt = “The magician bear is on the left, the alchemist bear is on the right, facing each other in the central park square.”
inputs = {
“image”: [image1, image2],
“prompt”: prompt,
“generator”: torch.manual_seed(0),
“true_cfg_scale”: 4.0,
“negative_prompt”: ” “,
“num_inference_steps”: 40,
“guidance_scale”: 1.0,
“num_images_per_prompt”: 1,
}
with torch.inference_mode():
output = pipeline(**inputs)
output_image = output.images[0]
output_image.save(“output_image_edit_plus.png”)
print(“image saved at”, os.path.abspath(“output_image_edit_plus.png”))
Why it matters
If the numbers hold up outside controlled tests, Qwen-Image pushes open-source generation into territory once reserved for private APIs. Brands that need posters in English and Chinese, UI designers who rely on Latin and logographic fonts, or chatbots that must generate presentation slides could all benefit from a system that treats text as first-class image content rather than a decorative afterthought.
The report also hints at a broader ambition. By equipping a vision-language model with strong generative skills, Alibaba envisions “vision-language user interfaces” where the assistant not only describes a scene but illustrates concepts on demand, rendering tables, flow charts or signage that the user can immediately edit. The same backbone already performs depth estimation and segmentation as by-products of its editing objective, an early sign that one model can unify perception and creation.
When compared to other models, Qwen-Image outperforms most of them. This can be seen in the image generation results for the same prompt, as analyzed using ChatGPT below-

Availability and next steps
The research team has released checkpoints, inference code and evaluation scripts under the Apache-2.0 license. Pre-trained weights, fine-tuned editing versions, and the enhanced VAE are hosted on both Hugging Face and ModelScope. Developers can try a web demo or pull the model into existing diffusion pipelines via an open-source adapter.
Looking forward, the authors say the same data pipeline can be extended to video, and the shared encoder already supports temporal inputs. They also point to the need for better safety filters before large-scale public deployment — a familiar caveat as generative systems become more accessible.
Read the full paper on Arxiv.
