Researchers at Apple have unveiled MANZANO, a new large-scale multimodal language model that aims to do two jobs at once: understand what is in an image and generate entirely new pictures from text prompts. The work, described in recent research released by the company’s AI/ML group, pairs a so-called “hybrid vision tokenizer” with a single, autoregressive language model. In early tests, a compact 3-billion-parameter version of MANZANO already matches or beats much larger rivals on image-question-answering tasks while producing on-prompt, photo-realistic images. A 30-billion-parameter edition widens the lead and, according to Apple’s internal evaluations, shows minimal trade-off between perception and creation—a tension that has haunted earlier unified models.
Why unifying vision and language still matters

Most consumer AI systems today fall into one of two camps. “Understanding-only” models such as LLaVA or Qwen-VL excel at reading charts and dense documents but are unable to sketch a scene. Pure generators, meanwhile, produce dazzling artwork yet stumble when asked detailed questions about an image. Apple’s researchers argue that a single model handling both directions—image to text and text to image—offers everyday benefits: multi-turn visual chat, image editing by instruction, and tighter grounding between what a model sees and what it makes. The catch has been a persistent performance tug-of-war. Techniques that help generation (discrete image tokens) often harm understanding, which prefers continuous visual features with more nuance.
Earlier projects tried to dodge the conflict with two separate tokenizers—one semantic encoder for perception and an auto-encoding VAE for generation. Apple’s team says that split forces the language model to juggle “two different languages of vision,” producing inefficiencies and accuracy drops, especially on text-heavy benchmarks like DocVQA and OCRBench. MANZANO’s headline idea is to keep a single visual backbone and offer two lightweight adapters on top, so both tasks share a common visual “alphabet.”
The hybrid tokenizer: one encoder, two adapters
At the front of the system sits a standard Vision Transformer. From there the hybrid tokenizer branches:
- Continuous adapter — It compresses the spatial grid and pipes rich, floating-point embeddings directly into the language model. This path is used whenever the model is answering questions about an image.
- Discrete adapter — Using finite scalar quantization, it turns the very same features into 64 K codebook indices. These IDs behave like ordinary words for the autoregressive decoder, making it straightforward to predict the next “image token” when a user wants a brand-new picture.
Because both adapters originate from the identical transformer encoder, MANZANO’s continuous and discrete tokens live in a shared semantic space. In practice that means the language model only has to learn one set of visual concepts, rather than reconciling two incompatible token streams.
A small, 300-million-parameter language model is first attached during tokenizer training so that both branches align with how the larger decoder ultimately represents language. Once alignment completes, the mini-decoder is discarded and the tokenizer becomes a frozen front-end for all later stages.
Training recipe in three stages
Apple’s engineers keep the rest of the pipeline deliberately simple, borrowing well-tested pieces from standard LLM and diffusion systems.
- Pre-training on 1.6 trillion tokens drawn from three streams—text-only, image-to-text captioning data, and text-to-image pairs. The mix is split 40 / 40 / 20 among the three sources.
- Continued pre-training with a smaller, 83-billion-token refresh of higher-quality data (multi-lingual OCR, reasoning-heavy images, synthetic captions) to sharpen both skills.
- Supervised fine-tuning on carefully curated instruction sets. Here the balance shifts slightly—roughly 41 % understanding, 45 % generation, and 14 % text-only—to polish instruction following without sacrificing language fluency.
During all stages the vision backbone and discrete adapter stay frozen, ensuring the image vocabulary remains stable. Loss weighting is kept simple: text tokens carry full weight, image tokens half. For rendering, MANZANO hands its predicted image IDs to an external diffusion decoder (a parameter-efficient DiT-Air design) that progressively upscales from 256 px to 2 048 px.
How MANZONO Stacks Up in Benchmarks
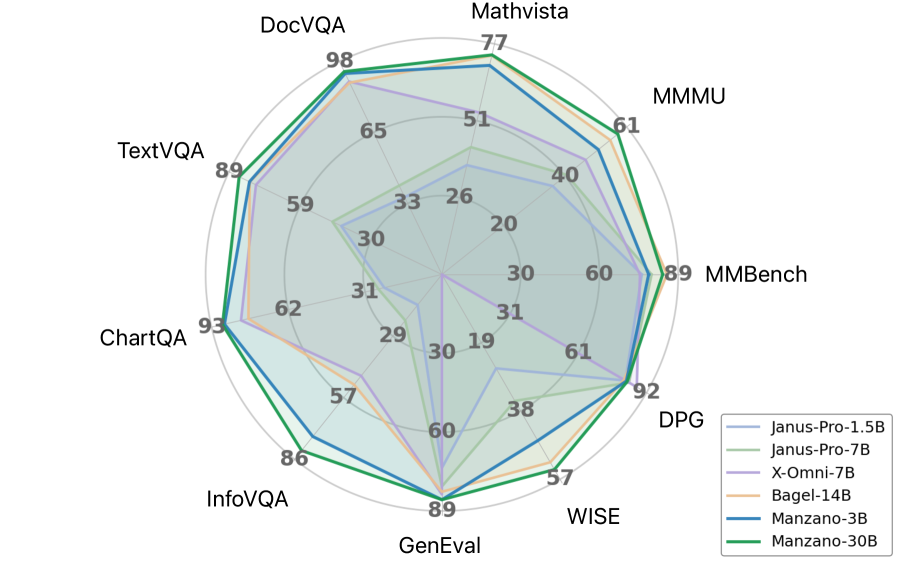
The team evaluated two public versions: MANZANO-3B and MANZANO-30B. On 12 prominent image-understanding benchmarks the smaller model already approaches or surpasses bigger specialist systems. Highlights include:
- ScienceQA — MANZANO-3B scores 92.9 %, edging past prior unified models and trailing only the very largest proprietary systems.
- DocVQA — At 75.0 % the 3B model tops all other unified contenders; the 30B edition pushes the score to 81.9 %.
- OCRBench — MANZANO-30B achieves 86.3 %, leading both specialist and unified peers listed in the study.
A tokenization ablation underscores why the hybrid approach matters. When the team forced the model to use discrete tokens for understanding, scores on text-rich tasks dropped sharply (e.g., an 8-point fall on ChartQA). A dual-encoder setup improved matters but still lagged the hybrid tokenizer across all categories.
Generation metrics tell a similar story. On GenEval, which grades prompt adherence, MANZANO-3B reaches an overall 0.85 score—competitive with 7- and 14-billion-parameter unified rivals. The 30B model maintains that mark while leaping ahead on WISE, a world-knowledge-grounded test (0.54 overall versus 0.46 for the 3B). Internal human raters also noted a 9.9-point gain in “structural integrity” of images when the team scaled only the diffusion decoder from 0.9 billion to 3.5 billion parameters, with no hit to language or generation scores.
| Model |
GenEval Overall |
WISE Overall |
| Bagel-14B |
0.82 |
0.52 |
| X-Omni-7B |
0.83 |
— |
| MANZANO-3B |
0.85 |
0.46 |
| MANZANO-30B |
0.85 |
0.54 |
Perhaps most telling: when Apple trained single-task variants (understanding only or generation only) the unified model kept pace, losing less than one percentage point on perception tasks and tying or beating generation baselines on five of six datasets. That suggests the hybrid tokenizer largely solves the conflict at the heart of joint vision-language modelling.
From Playful Images to Precise Edits
Because MANZANO’s diffusion decoder can also accept a reference image, the researchers extended the system to common editing chores without changing weights. Give it a photo plus the instruction “replace the sky with a sunset,” and the LLM handles the instruction semantics while the diffusion block enforces pixel-level consistency. The team reports successful trials in style transfer, in-painting, out-painting, and even producing a dense depth map—all from the same backbone.
One qualitative comparison in the research shows MANZANO-30B generating a surreal but coherent scene (“The bird is flying below the elephant”) at visual quality that human graders found on par with outputs from GPT-4o and other leading generators. More routine prompts—street signs with legible text, multi-object spatial layouts—also show steady improvement as the language decoder scales from 300 M to 30 B parameters.
What Comes Next?
Apple’s study stops short of announcing any shipping product, but the architecture slots neatly into today’s LLM pipelines. Components are decoupled, objectives standardised, and scaling behaviour looks healthy on both language-centric and image-centric axes. The authors hint at future directions: conversational editing, deeper reasoning, and perhaps expansion into other modalities. For now, the takeaway is straightforward. By letting a single vision encoder speak two dialects—continuous for comprehension, discrete for creation—MANZANO narrows the gap between seeing and imagining without making users choose one skill over the other.
